How Does a Property Data API Work?
Learn how a property data API works, its features, and how you can use it for real estate and business insights.
.png)

For production-grade property data workloads, a structured real estate API consistently outperforms web scraping on reliability, legal safety, and long-term cost.
If your pipeline is built on scrapers, the question is not whether to migrate to an API, but when the next breakage will force you to.
The debate over real estate API vs web scraping comes up the moment a team decides to build something serious with property data. Both approaches can pull information from the web, but they differ significantly in reliability, compliance risk, and the engineering work required to keep them running. As the PropTech sector grows toward a projected $114 billion by 2033, the volume and velocity of property data flowing through real estate platforms has made this choice more consequential than ever. Teams that built on scraping in the early stages frequently hit a wall when they try to scale. Structured property data at scale is simply a different problem than pulling a few listings for a prototype.
This guide breaks down the practical tradeoffs between a dedicated real estate API and web scraping real estate data, including where each approach makes sense, where scraping creates real problems, and what to look for in an API if you decide to make the switch.
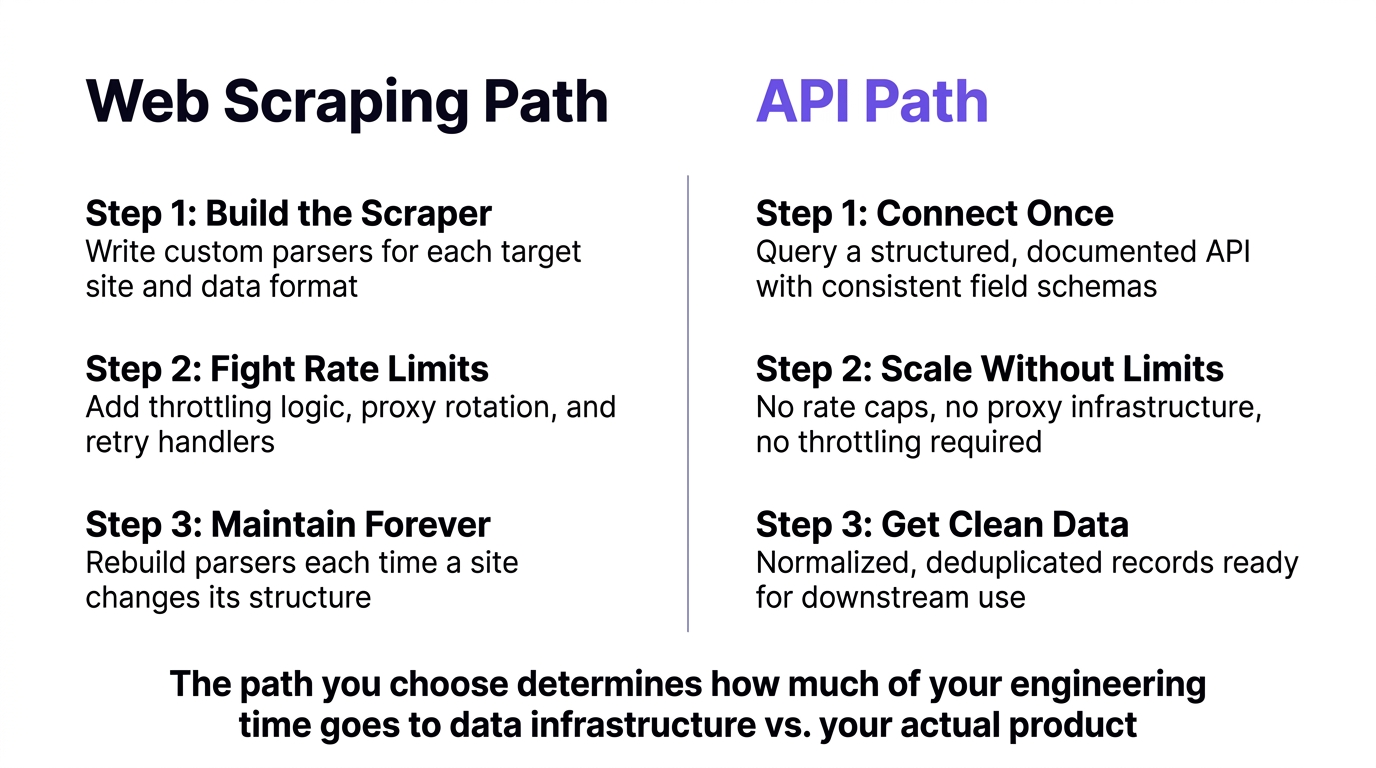
The distinction is more fundamental than it might appear. When teams evaluate real estate API vs web scraping as data strategies, they are choosing between two fundamentally different models. A real estate API is a purpose-built data delivery system: a provider aggregates, structures, and maintains property records, and developers query that system through a documented interface. Web scraping real estate data means running automated bots against public-facing websites, parsing HTML, and transforming whatever structure you find into something usable. The first approach is a partnership. The second is a workaround.
A structured real estate API returns clean, normalized records in consistent formats, typically JSON or CSV. Fields are predictable, schemas are documented, and the provider handles sourcing updates as data changes. When you query for property records by location, type, or other attributes, you get back exactly what you asked for, without needing to interpret markup or handle rendering quirks.
Most production-grade APIs also provide full API documentation that covers query structure, available fields, filter syntax, and response examples. That transparency matters because it means developers can plan integrations, estimate data coverage, and troubleshoot without a sales conversation.
The underlying data in a well-maintained real estate API comes from authoritative sources: public records, county assessors, tax filings, and aggregated listing data. A good provider handles deduplication, normalization, and refresh cadence. Your team inherits the benefit of that infrastructure without building it yourself.
Web scraping real estate data means deploying bots that load web pages, parse HTML structure, and extract field values from wherever they appear on the page. The scraper has to be tailored to each target site, and it has to be updated every time that site changes its layout, adds anti-bot measures, or shifts how data is rendered. For a single site accessed occasionally, this is manageable. For production workloads hitting multiple sources at scale, it becomes a significant ongoing maintenance problem.
Sites actively defend against scraping. CAPTCHAs, IP rate limits, JavaScript rendering requirements, fingerprinting, and dynamic content loading all add engineering complexity. A scraper that worked cleanly last quarter may fail silently or start returning garbage data after a site update, and you may not notice until downstream systems are affected.
Rate limiting is one of the most underestimated costs of property data scraping. When you scrape a website, you are not a paying customer of that data. You are an uninvited guest, and sites enforce that distinction aggressively. Most major real estate portals implement request-per-second caps, session timeouts, and progressive blocking that ramps up once a bot signature is detected. The result is that scraping at scale requires far more than a bot. It requires a throttling layer, a retry handler, a proxy rotation infrastructure, and monitoring to detect when the whole system quietly breaks.
Consider what a developer actually has to build to maintain reliable scraping of property data at meaningful volume. Requests need to be paced below detection thresholds, which means adding artificial delays and concurrency limits. When requests fail, a retry handler has to decide whether the failure was a transient error, a block, or a structural change to the target page. Proxy pools need to be rotated to avoid IP-based blocks. Each of these is an engineering problem that has nothing to do with the actual product you are trying to build.
For teams that need to run large queries, backfill historical data, or power real-time applications, this matters. The absence of rate limiting is a hard prerequisite for building pipelines that actually work under load. It is what makes large-scale, real-time property data access possible without engineering workarounds.
It is worth noting that AI-powered scraping tools do not change this equation. Modern AI scrapers are still subject to robots.txt directives, IP-based blocking, CAPTCHA enforcement, and rate limits imposed by the target site. A site that blocks automated access blocks AI agents the same way it blocks any other bot. The underlying friction does not disappear because the scraper is smarter.
A purpose-built data aggregation API operates differently from a scraped pipeline. When a provider has already ingested and structured the data, your query goes to their system, not to a third-party website. There is no target site imposing rate limits on your requests. You are querying a database, not scraping a portal.
This distinction has a direct impact on what your team has to build. Without artificial throughput restrictions, there is no throttling logic to write, no retry handler for IP blocks, and no proxy infrastructure to maintain. You send a query, you get structured property data records back. The engineering complexity of managing throughput against a hostile target disappears entirely.
For teams that need to run large queries, backfill historical data, or power real-time applications, this matters. The absence of rate limiting is a hard prerequisite for building pipelines that actually work under load. It is what makes large-scale, real-time property data access possible without engineering workarounds.
When you use a data aggregation API from a provider who has a contractual right to license that data, your legal exposure is fundamentally different. The provider has taken on the responsibility of sourcing data appropriately, maintaining terms of service relationships, and ensuring their product complies with applicable law. You are a customer of a licensed service, not an operator of a scraping stack running against websites that have explicitly prohibited it.

This distinction matters for enterprise procurement, for regulated industries like mortgage lending and insurance, and for any product where data provenance needs to be documented. Scraping creates a chain of custody problem. APIs create a documented, contractual relationship with a known data provider.
The real estate API vs web scraping comparison comes into sharpest focus when teams evaluate data quality in production. Scraped data is only as good as the HTML it came from. Structured API data is only as good as the provider's sourcing and normalization. Both can be high quality. But the work required to get there is very different.
When you scrape property data from multiple sources, each site represents data differently. Square footage might be listed as "1,450 sq ft" on one site and "1450" on another. Bedroom counts might be stored as integers, text, or range values. Addresses have dozens of formatting variations. Getting this data into a consistent schema for downstream use requires a normalization layer that is often as complex as the scraping infrastructure itself.
Field coverage is also inconsistent. A site may expose listing price and address but not tax assessment history, ownership records, or property type classification. Building a complete property record from scraped sources usually means stitching together multiple pipelines, each with its own maintenance burden.
A well-maintained real estate API delivers records with consistent field names, normalized values, and coverage across property types. Residential, commercial, and industrial properties appear in the same schema under the same integration, which means a team building for multiple asset classes does not need separate pipelines. The data aggregation work, deduplication, and schema standardization has already been done.
Credit-based pricing models, where you pay per record delivered rather than per query attempted, also align API cost directly with data received. Failed queries do not consume credits. This is structurally different from building scraping infrastructure where every failed request, retry, and proxy rotation has an engineering and infrastructure cost whether or not usable data comes back.
Web scraping can work well for prototypes, competitive research, or narrow data pulls from a small number of sources. For teams still on the fence about real estate API vs web scraping, these friction points tend to make the decision for them. If several of these sound familiar, the scraping infrastructure has likely become a bottleneck.
Not all real estate APIs are equivalent. Once teams resolve the real estate API vs web scraping question in favor of an API, provider selection becomes the next critical decision. These are the criteria that separate production-ready APIs from ones that recreate the reliability problems you were trying to escape.
A real estate API should cover residential, commercial, and industrial properties under a single integration. Providers that separate property types into different products or tiers create friction when your use case expands. If you are building for investors who operate across asset classes, a single integration that returns all property types saves significant engineering work.
National coverage is equally important. APIs that organize data by metro area or region force you into multiple contracts as your geographic footprint grows. Look for data products spanning all markets nationally with no per-region packaging and no separate contracts for different markets.
The quality of a provider's documentation tells you a lot about how they treat developers as customers. If understanding query syntax, available filters, or response field definitions requires a sales call, that is a problem. Production integrations require the ability to troubleshoot, explore edge cases, and understand schema changes without waiting on account management.
Public documentation that covers query structure, field definitions, filter options, and response examples is a baseline requirement, not a differentiator. Before committing to any API, verify that the documentation covers what you actually need to build with, rather than surface-level examples designed to attract prospects.
Per-record pricing, where you pay for data delivered rather than queries attempted, aligns API cost with actual value received. If a query returns no results, you should not be charged for it. This is structurally different from per-request models where failed queries, empty result sets, and retries all consume quota.
Evaluate whether the pricing structure allows you to scale without penalty. Geographic coverage packages with per-region pricing create the same scaling friction as expanding a scraping operation: you are managing multiple pricing relationships instead of one.

Scraping is most defensible when no API exists for the specific data you need, when the volume is low, when you have reviewed and are operating within the target site's terms of service, and when the use is non-commercial or academic. For production workloads at scale, particularly in regulated industries or enterprise contexts, the maintenance burden, legal exposure, and data quality problems of scraping generally outweigh the cost savings compared to a structured API.
A well-built real estate API covers property characteristics like square footage, bedroom and bathroom counts, lot size, property type, and year built. It also includes location and address data, ownership and transaction history, tax assessment records, listing data, and status. Coverage varies by provider. Before integrating, verify that the specific fields your application requires are actually available and consistently populated, rather than appearing in a schema with sparse or unreliable coverage.
Update cadence varies by provider and data type. Listing data typically refreshes more frequently than ownership or tax records, which may update on county recorder schedules. A good API provider documents their refresh cycles and data sourcing clearly. If data freshness is critical to your use case, ask specifically about how often each field category is updated and what sources the provider draws from.
For most production use cases, yes. A data aggregation API that covers all property types nationally with consistent schemas typically consolidates what would otherwise be multiple separate scraping pipelines. The tradeoff is that you are relying on the provider's sourcing decisions rather than controlling your own. The upside is that normalization, deduplication, and refresh management are handled for you, and the provider's sourcing relationships carry cleaner legal standing than scraped pipelines.
The real estate API vs web scraping decision is ultimately a question of what you are trying to build and how long you plan to run it. Scraping can get a prototype off the ground quickly, and for narrow, low-volume use cases, it may continue to work well. But for any team building production systems, the maintenance cost, legal exposure, and data quality limitations of property data scraping compound over time.
Rate limiting imposed by target sites is an architectural constraint, not a minor inconvenience. It forces developers to build and maintain infrastructure that has nothing to do with the product itself. The throttling logic, proxy rotation, retry handling, and pipeline monitoring required to keep a scraping operation functional at scale represent real ongoing engineering cost.
Datafiniti's structured property data API gives development teams access to over 280 million property records spanning residential, commercial, and industrial assets, with no artificial rate limits, full national coverage, and per-record pricing that charges only for data received. Teams that have spent engineering cycles maintaining scraping infrastructure consistently find that the migration simplifies their stack considerably. Get in touch to see what's possible with clean, structured property data built for production.

Learn how a property data API works, its features, and how you can use it for real estate and business insights.

Discover what makes the best real estate APIs stand out. Learn about essential features for your property data needs.
Learn about the benefits of a real estate MLS API for streamlining data access and driving business growth.

Learn why a MLS database API is vital for real estate pros. Get data, insights, and competitive edge.
Learn how to access MLS listing data using an MLS data API. Discover Datafiniti's solutions and integration tips.
.png)
.jpeg)

Explore the benefits and technicalities of a real estate listing API. Learn how to choose the right provider and integrate data for business growth.

Unlock the MLS database with APIs. Learn how to access property data, gain real estate insights, and integrate MLS data for your business needs.

Discover how property APIs with ownership details empower real estate tech startups. Learn about data integration, risk mitigation, and driving business value.
Unlock the value of product catalog sync for product managers. Streamline data, improve decisions, and reduce costs with real-time insights.

Learn about product data webhooks, their components, and how they enable real-time updates for business intelligence and workflow automation.

Unlock insights with product data API integration. Essential for analysts & product managers to streamline data access & enhance product strategy.

Learn about product data APIs, their benefits, and how they drive business growth. Explore integration and advanced use cases.

Learn what ecommerce data vendors do, their services, and how to choose the right one for your business growth.

Compare product data providers. Learn what to look for in data quality, structure, and integration features.

Learn how to leverage real-time product data APIs for e-commerce, competitive analysis, and AI. Get instant access to clean, structured product data.

Find the best product data API with real-time updates, comprehensive coverage, and a user-friendly portal. Explore features to look for.

Access property data with a powerful property database API. Explore listings, market analysis, investment opportunities, and more. Get started today!

Unlock commercial real estate insights with a powerful API. Access property data, streamline workflows, and enhance investment strategies.
Learn how to get a real-time product feed using an API. Access, leverage, and ensure accuracy of product data for your business needs.

Learn how to gather and analyze competitor pricing data to inform your business strategy. Understand key components and ethical considerations.

Enhance your product data with comprehensive enrichment. Discover insights, drive growth, and choose the right approach for your business.
.png)
.png)
.png)
.png)
Learn how to leverage a product catalog API for business growth. Discover data quality, access methods, and strategy for your product catalog API.

Optimize your ecommerce product data feed for growth. Learn strategies, leverage technology, and ensure data quality for better customer experience and AI initiatives.

Explore the benefits and integration of a product search API. Streamline your product discovery and leverage data for business growth.
.png)
.png)
.png)
.png)
.png)
MLS API vs IDX: Explore the differences in real estate data access, retrieval, and integration. Understand which solution fits your needs.
Compare web scraping vs real estate API for data acquisition. Learn the pros, cons, and best use cases for each method.

Unlock housing sales analytics insights with Datafiniti. Explore property data, market trends, and advanced techniques for strategic decisions.

Leverage the property valuation API for real estate insights. Access comprehensive property data for diverse applications with Datafiniti.

Learn about product data APIs explained. Discover how to access, integrate, and utilize product data for e-commerce, analytics, and more.

Unlock ecommerce data with APIs for business insights, product catalog enrichment, and competitive analysis. Explore data via portal or API.

Explore housing sales API data for insights. Access property data, integrate into applications, and gain business intelligence. Get started today!

Access, analyze, and use real estate ownership data at scale. Learn how to find, process, and leverage this crucial information for business insights.

Unlock opportunities with bulk real estate transaction data. Learn how to access, analyze, and leverage property data for investing, marketing, and more.
Explore what a property sales database is, its core components, how to access data, and key use cases for real estate analysis and more.

Unlock insights with housing transaction data. Analyze markets, investments, sales, and risk. Get comprehensive property data for informed decisions.

Explore real estate transaction databases: understand data components, access methods, and leverage property data for insights and advanced applications.
Understand IDX vs MLS API differences. Learn about data access, integration, and how Datafiniti's solutions empower real estate professionals.

Explore the MLS database API: understand its components, benefits, and how to access real estate data for various applications. Learn about its core functionality and technical aspects.

Learn how a property database API can help real estate pros analyze trends, monitor listings, and optimize strategies. Get data insights.

Explore what a residential property API is, its features, benefits, and real-world applications for real estate professionals and investors.

Explore commercial real estate API functionality, data integration, and use cases. Learn how to leverage property, business, and people data for insights.

Learn about MVP data integration, its components, benefits, and strategies for accessing and utilizing data resources effectively.

Learn how to choose the best property data API. Explore features, providers, pricing, and integration for real estate insights.

Explore real estate database API options. Learn about data quality, features, and how to choose the right provider for your needs.
.png)

Understand how a product data API works, its key features, integration methods, and applications for e-commerce and business intelligence.

Explore how data aggregation platforms work, their capabilities, and applications. Learn to choose and implement the right platform for your business intelligence needs.

Discover why property data aggregation is crucial for businesses. Streamline access, empower functions, enhance risk management, and drive strategic decisions with authoritative insights.

.jpeg)
Discover the best MLS data API features, including real-time updates, bulk downloads, and flexible filtering for property data.

Explore the functionality and benefits of a product data API. Learn how to integrate, leverage, and choose the right provider for your business insights.
Understand the difference between Product Search API and Product Data API. Learn how to leverage product data for business intelligence and analytics.

Access real estate transaction data via API. Explore property insights, sales, underwriting, and advanced applications with our authoritative guide.

Explore the benefits of a real estate MLS API for enhanced data access, streamlined workflows, and market responsiveness. Learn about key features and use cases.

Explore the MLS database API for comprehensive property data access. Learn about its core functionality, key features, and integration into real estate technology.

Explore the capabilities of a property data API. Understand its core functionality, key features for developers, and how to access property information at scale for business insights.
.png)
.jpeg)
Choosing the right property market API is critical for investment platforms. Learn how to evaluate data depth, coverage, freshness, and integration quality before you commit.